I have a lot of images on my computer, random fanart from the web, screenshots of movies I have seen, etc. I recently saw that one of my image folders was 80 GB big, so it is no wonder I care much about image compression.
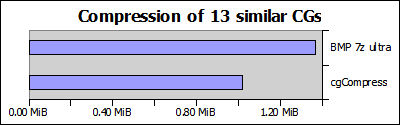
I was looking through a visual novel CG collection when I thought: shouldn’t this be able to compress well? After all, VN CGs tend to have a lot of similar images with minor modifications like different facial expressions. So I did a quick test, how well does it compress using different lossless compression algorithms:

As expected, PNG is quite a bit better than simply zipping BMP images, and WebP fares even better. However what is this, compressing BMP images with 7z literally kills the competition!
The giant gap from ZIP to 7z does not come from the fact that LZMA is superior to Deflate, but because ZIP only allows files to be compressed individually while 7z can treat all files as one big blob of data. This is also why a general purpose compression algorithm can beat the ones optimized for images, as PNG and WebP also compresses images individually.
Note to the comparison: Usually CG collections have an average of 2-3 versions of each image, here we checked on an extreme case with 13 versions. This obviously exaggerates the results, but the trend still stands.
Doing it better
BMP is the superior solution? There is no way I can accept that, we need to do something about that!
If you have ever worked with GIF animations you properly know that you can reduce the size if you only change the differences between each frame. That is exactly what we want to do, but to use PNG and WebP to compress that difference. The problem is that we need to store the differences and information on how those should interact to recreate all the images, and there isn’t a good file format to do that.

So I have created a format based on OpenRaster, which is a layered image format to compete with PSD (Photoshop) and XCF (GIMP). I wanted to use it without modifications, but having multiple images in one file, while planned, appears to be far into the future. (I want it now!) It is basically a ZIP file which contains ordinary image files and a XML document describing layers, blend modes, etc.
Next part is automatically creating such a file from a series of images. For this I have written cgCompress (Github page) and while there is still a lot of work to be done, it has proven that we can do it better. Fundamentally this is done by creating all the differences and then with an greedy algorithm, select the ones which will add the least to the total file size. This continues frame by frame until we have recreated all the original images. I have also worked with a optimal solver, but I have not been able to get it to work with more that 3-5 images (because of time complexity).
Using the greedy algorithm I managed to reduce the file size 25.6% compared 7z compressing BMP images: (Lossless WebP used internally)
This is a compression rate of a whooping 88.7%! Of course, this is only because we are dealing with 13 very similar images. 67.2% of the file size is the start image and without a better image compression algorithm, we can do very little to improve that. That means the 12 remaining images use each 2.7% each (1/13 is 7.7%), not much to work with but I believe I can still make improvements.
This is just one case though, while uncommon, some images still need further optimization to get near-perfect results. I have tried compressing an entire CG collection of 154 images and my results where as following:
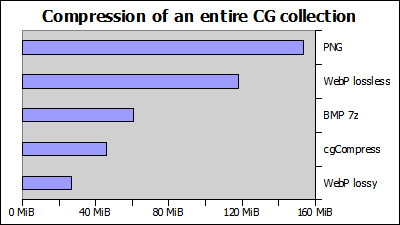
Compared to 7z compressed BMP, there was an improvement of 24.0% and compared to WebP it is 61.1%. On average, the set contained 3.92 variations per image; cgCompress manages to do 2.57 as many images compared to ordinary WebP. The difference between those two numbers is the overhead cgCompress requires to recreate all 3.92 variations per image and it depends on how different the variations are. While I don’t know how low it can get, I do believe there is room for improvement here.
I included lossy WebP here as well (done at quality 95) to give a sense of difference between lossless and lossy compression. cgCompress definitively closes the gap, but if you don’t care about your images lossy WebP is still the way to go. (It should be possible to use lossy compression together with the ideas used in cgCompress though.)
Conclusion
cgCompress can significantly reduce the space needed to store visual novel CG collections. While only a moderate improvement of ~25% over 7z compressed BMP, compressed archives only works well for archiving or transferring over networks. cgCompress, as based on OpenRaster, has proper thumbnailing, viewer support and potentially meta-data. With PNG and WebP being the direct contenders, cgCompress provides a big leap in compression ratio.
On a personal note, going from concept to something I can use in 8 days is quite an achievement for me. While the cgCompress code isn’t too great, I’m still quite happy on how this turned out.
Tags: cg, compression, visual novel, WebP